Развитие искусственного интеллекта привело к тому, что мощные модели теперь доступны не только в облаке, но и на домашних компьютерах. Однако выбор подходящей модели часто становится проблемой: пользователь не всегда знает, какая нейросеть уместится в его видеокарту и оперативной памяти. Чтобы решить эту дилемму, энтузиасты создали удобный инструмент WhatModelsCanIRun, который позволяет мгновенно проверить совместимость вашего железа с популярными моделями.
Как работает инструмент проверки
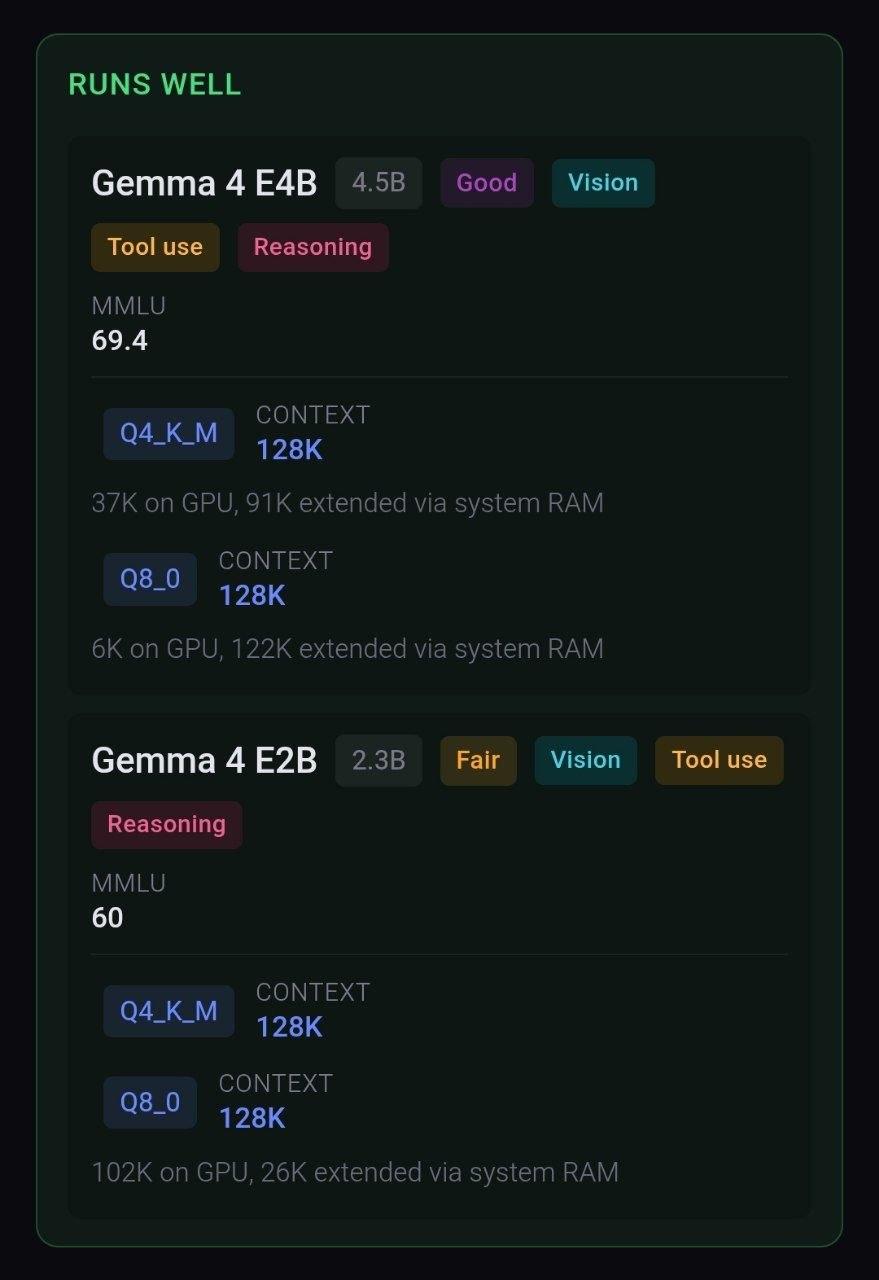
Сервис представляет собой интерактивный калькулятор, который анализирует ключевые параметры вашего оборудования. Вам необходимо ввести количество видеопамяти (VRAM) и объем оперативной памяти (RAM). После этого система автоматически рассчитывает, какие модели нейронных сетей можно запустить локально. Результатом становится подробный отчет, включающий не только название модели, но и прогнозируемую скорость генерации, а также размер контекстного окна, которое она поддерживает.
Поддержка различных архитектур
Особое внимание разработчики уделили универсальности решения. Инструмент корректно определяет и учитывает особенности оборудования от разных производителей. Это означает, что вы можете проверить возможности как для классических видеокарт NVIDIA, так и для решений от AMD и процессоров Intel. Кроме того, сервис учитывает специфику архитектуры Apple Silicon, что открывает возможности для владельцев мощных ноутбуков и рабочих станций на базе чипов M1, M2 и M3.
- Определение VRAM: Точный расчет места для загрузки весов модели.
- Оценка скорости: Прогноз времени генерации одного токена.
- Контекстное окно: Информация о том, сколько текста модель способна запомнить.
- Сравнение моделей: Возможность выбрать между Llama 3, Mistral, Stable Diffusion и другими.
Для разработчиков и энтузиастов, планирующих развернуть локальную LLM (Large Language Model) или генеративную модель изображений, этот инструмент становится мастхевом. Он помогает избежать ситуации, когда модель не загружается из-за нехватки памяти, или работает слишком медленно, что делает её непригодной для практического использования.
Значимость для локального ИИ
Тренд на приватность и независимость от облачных сервисов заставляет пользователей искать способы запускать ИИ на своем устройстве. Использование локальных моделей позволяет обрабатывать данные без их отправки на сторонние серверы, что критически важно для работы с конфиденциальной информацией. Сервис WhatModelsCanIRun упрощает вход в этот мир, предоставляя четкие ориентиры для выбора модели под конкретное железо. Это особенно актуально в условиях, когда бесплатные тарифы облачных API могут быть ограничены или недоступны.
Использование таких инструментов способствует более осознанному выбору программного обеспечения и помогает максимизировать производительность имеющегося оборудования. Даже если у вас нет топовой видеокарты, с помощью правильного выбора модели и оптимизации (например, использования квантованных версий) можно получить вполне рабочий и полезный ИИ-ассистент прямо на рабочем столе.



